
How does our understanding shape the insights we extract from data?
The concept of perception in data mining will be discussed in this article, as well as its significance and impact. By studying how cognitive processes are developed, we will gain a better understanding of how human insight can be translated into machine insights.
We’ll take a journey to discover the mysteries of perception in data mining and discover how it shapes our understanding of the world around us.
Understanding Perception
Understanding perception is paramount in the landscape of data mining, where the convergence of human cognition and computational analysis unravels the mysteries hidden within vast datasets. At its core, perception can be succinctly defined as the mental process of interpreting sensory information, encompassing not only what we see, hear, or touch but also how we make sense of it. In the realm of data mining, perception serves as the cornerstone upon which insights are built, acting as the guiding force that steers the course of analysis and decision-making.
The importance of perception in data mining cannot be overstated, as it serves as the lens through which we navigate the complexities of information overload. In essence, perception acts as the catalyst for uncovering patterns, trends, and anomalies within datasets, transforming raw data into actionable insights. By leveraging our innate ability to perceive and interpret data, we can extract valuable knowledge that drives informed decision-making across various domains, from finance and marketing to healthcare and beyond.
Moreover, the role of perception extends beyond mere data interpretation; it fundamentally shapes the way we extract insights from the information at hand. Whether through visualizations, statistical analyses, or machine learning algorithms, perception underpins every step of the data mining process, guiding researchers and analysts towards meaningful discoveries. It is through the lens of perception that we discern meaningful patterns from noise, identify correlations between variables, and ultimately derive actionable intelligence from seemingly disparate datasets.
In essence, understanding perception in the context of data mining is not just about recognizing the importance of human cognition in the analytical process but also about embracing the symbiotic relationship between perception and computational analysis. By acknowledging the pivotal role that perception plays in extracting insights from data, we can unlock new avenues for innovation, discovery, and problem-solving in an increasingly data-driven world. As we delve deeper into the intricacies of data mining, it becomes evident that perception is not merely a cognitive process but rather a fundamental aspect of our quest to unravel the mysteries of the digital age.
Fundamentals of Data Mining
Delving into the fundamentals of data mining unveils a multifaceted discipline that lies at the intersection of computer science, statistics, and artificial intelligence. Here, we embark on a journey to explore the core principles that underpin this transformative field, from its foundational concepts to its myriad applications shaping industries worldwide.
Introduction to Data Mining
At its essence, data mining can be perceived as the art and science of uncovering hidden patterns, correlations, and insights within vast datasets. It serves as a powerful tool for extracting knowledge from raw data, enabling organizations to make informed decisions, predict future trends, and gain a competitive edge in today’s data-driven landscape. From customer segmentation and market basket analysis to fraud detection and predictive modeling, the applications of data mining are as diverse as they are impactful.
Basic Concepts and Techniques
Central to the practice of data mining are a plethora of fundamental concepts and techniques that form the building blocks of analysis. These include but are not limited to:
- Data Preprocessing: A crucial step in the data mining pipeline, data preprocessing involves cleaning, transforming, and reducing the dimensionality of raw data to improve its quality and usability for analysis.
- Exploratory Data Analysis (EDA): EDA techniques such as summary statistics, data visualization, and correlation analysis provide insights into the structure and characteristics of the dataset, aiding in the identification of patterns and trends.
- Statistical Modeling: Statistical methods such as regression analysis, clustering, and classification enable data miners to uncover relationships between variables, classify data into meaningful groups, and make predictions based on historical patterns.
- Machine Learning Algorithms: From decision trees and random forests to support vector machines and neural networks, machine learning algorithms play a pivotal role in data mining by automating the process of pattern recognition, prediction, and optimization.
Objectives and Applications
The objectives of data mining extend beyond mere exploration and analysis; they encompass a broader spectrum of goals aimed at driving value and innovation. Some common objectives of data mining include:
- Knowledge Discovery: Uncovering previously unknown patterns, trends, and relationships within data to generate actionable insights and inform decision-making processes.
- Predictive Modeling: Building predictive models that forecast future outcomes based on historical data, enabling organizations to anticipate trends, mitigate risks, and capitalize on opportunities.
- Pattern Recognition: Identifying recurring patterns and anomalies within data to detect fraud, optimize business processes, and enhance operational efficiency.
Moreover, the applications of data mining span a wide range of industries and domains, including finance, healthcare, retail, telecommunications, and more. From personalized recommendation systems and credit scoring models to disease diagnosis and supply chain optimization, data mining revolutionizes the way organizations extract value from their data assets, driving innovation, and competitive advantage in an increasingly data-driven world.
In essence, the fundamentals of data mining serve as the bedrock upon which organizations build their analytical capabilities, leveraging data-driven insights to drive strategic decision-making, enhance operational efficiency, and unlock new avenues for growth and innovation. As we continue to explore the ever-evolving landscape of data mining, it becomes clear that its transformative potential knows no bounds, shaping the future of industries and societies alike.
Perception in Data Mining
Exploring the intricate interplay between human cognition and computational analysis unveils the profound impact of perception in the realm of data mining. Here, we delve into the cognitive processes involved, dissect the nuances of human versus machine perception, and elucidate its profound influence on data analysis.
Cognitive Processes Involved
At the heart of perception in data mining lie a myriad of cognitive processes that shape how we interpret and extract insights from complex datasets. These processes include:
- Pattern Recognition: The ability to identify meaningful patterns, trends, and relationships within data, enabling data miners to discern signal from noise and extract actionable insights.
- Attention and Focus: The selective allocation of attention to relevant features or variables within the dataset, guiding the analytical process towards areas of interest and significance.
- Memory and Recall: The storage and retrieval of information from memory, allowing data miners to draw upon past experiences and knowledge to inform their analysis and decision-making.
- Inference and Interpretation: The process of making logical deductions and interpretations based on available evidence, facilitating the generation of hypotheses and insights from data.
Human vs. Machine Perception
A key distinction in perception lies in the comparison between human and machine capabilities, each offering unique strengths and limitations in the context of data mining. While humans excel in intuitive reasoning, creativity, and contextual understanding, machines possess unparalleled computational power, scalability, and speed. However, the convergence of human expertise and machine learning algorithms often yields optimal results, leveraging the complementary strengths of both to enhance the accuracy and efficiency of data analysis.
Influence on Data Analysis
The influence of perception extends far beyond mere data interpretation; it fundamentally shapes the way we approach, analyze, and derive insights from the information at hand. By leveraging human intuition, domain expertise, and contextual understanding, data miners can uncover nuanced insights that may elude purely algorithmic approaches. Furthermore, perception serves as the guiding force that steers the course of analysis, influencing the selection of methodologies, techniques, and visualization tools employed to extract meaningful insights from the data.
In essence, perception in data mining transcends the realm of mere cognition, intertwining human expertise with computational analysis to unlock the full potential of data-driven insights. By understanding the cognitive processes involved, recognizing the distinctions between human and machine perception, and harnessing the influence of perception on data analysis, organizations can harness the transformative power of data mining to drive innovation, inform decision-making, and gain a competitive edge in an increasingly complex and interconnected world.
Factors Affecting Perception
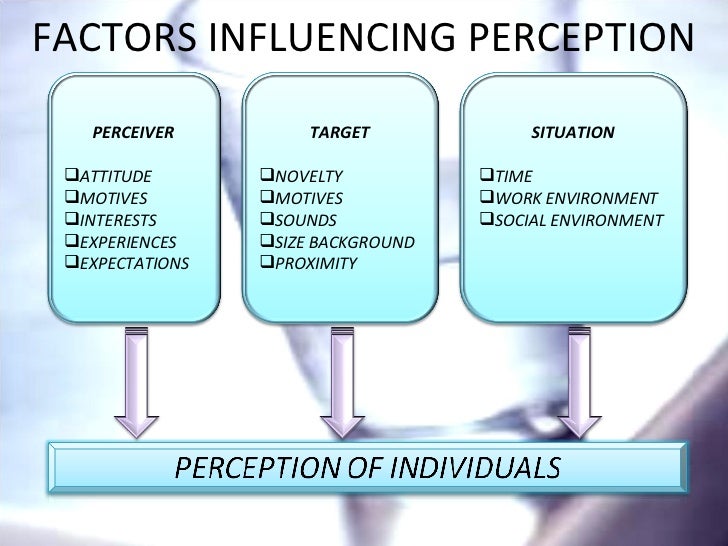
Exploring the nuanced factors that influence perception in data mining unveils a complex interplay between data quality, context, bias, and subjectivity. Here, we delve into the key determinants shaping how we interpret and derive insights from data, from the quantity and quality of the information at hand to the context in which it is analyzed and the biases that may color our interpretation.
Data Quality and Quantity
The quality and quantity of data serve as foundational pillars upon which perception in data mining rests. Key considerations include:
- Accuracy and Completeness: Ensuring that the data accurately reflects the phenomenon being studied and is comprehensive enough to provide meaningful insights.
- Relevance and Timeliness: Assessing the relevance of the data to the analysis at hand and ensuring that it is up-to-date and reflective of current trends and patterns.
- Consistency and Reliability: Verifying that the data is consistent across sources and reliable in its representation of the underlying reality.
Ultimately, the quality and quantity of data directly impact the accuracy and reliability of our perceptions and insights, influencing the validity of conclusions drawn from the analysis.
Context and Background Knowledge
Context plays a crucial role in shaping how we perceive and interpret data, influencing our understanding of its significance and implications. Key factors include:
- Domain Expertise: Drawing upon background knowledge and expertise in the relevant field to contextualize and interpret the data within its broader framework.
- Cultural and Social Context: Recognizing the cultural and social factors that may influence perceptions and biases, such as societal norms, values, and beliefs.
- Temporal and Spatial Context: Considering the temporal and spatial dimensions of the data, including historical trends, geographical variations, and contextual factors that may impact interpretation.
By situating the data within its appropriate context and drawing upon relevant background knowledge, data miners can enhance the accuracy and relevance of their perceptions, leading to more informed decision-making and analysis.
Bias and Subjectivity
Perhaps one of the most pervasive factors influencing perception in data mining is the presence of bias and subjectivity. Key considerations include:
- Confirmation Bias: The tendency to seek out information that confirms preconceived beliefs or hypotheses, leading to selective perception and interpretation of data.
- Cognitive Biases: Various cognitive biases, such as availability heuristic, anchoring bias, and framing effect, that distort perceptions and decision-making processes.
- Subjective Interpretation: The inherent subjectivity in data interpretation, influenced by personal experiences, perspectives, and cognitive heuristics.
Addressing bias and subjectivity in data mining requires a conscious effort to recognize and mitigate potential sources of bias, employ diverse perspectives and methodologies, and foster a culture of critical thinking and reflexivity within the analytical process.
In essence, the factors affecting perception in data mining are multifaceted and interconnected, encompassing considerations of data quality, context, bias, and subjectivity. By understanding and addressing these factors, data miners can enhance the accuracy, reliability, and relevance of their perceptions, unlocking deeper insights and driving more informed decision-making in an increasingly complex and data-driven world.
Techniques to Enhance Perception

Unlocking the full potential of perception in data mining necessitates the adoption of innovative techniques and methodologies aimed at enhancing our ability to interpret, analyze, and derive insights from complex datasets. Here, we delve into three key techniques that serve as linchpins in the quest to enhance perception: data visualization, feature engineering, and interpretability and explainability.
Data Visualization
Data visualization stands as a cornerstone technique in enhancing perception, offering a powerful means of transforming raw data into intuitive, insightful visual representations. Key considerations include:
- Graphical Representations: Utilizing charts, graphs, and maps to convey complex relationships and patterns within the data in a visually digestible format.
- Interactive Dashboards: Creating interactive dashboards and visualizations that enable users to explore and manipulate data dynamically, fostering deeper understanding and insights.
- Storytelling with Data: Employing storytelling techniques to narrate compelling narratives and insights derived from the data, engaging and captivating audiences while conveying key messages effectively.
By harnessing the power of data visualization, organizations can amplify their ability to perceive and understand the underlying patterns and trends within their datasets, empowering data-driven decision-making and innovation.
Feature Engineering
Feature engineering emerges as a crucial technique in enhancing perception, focusing on the creation and selection of informative features that drive the predictive power of machine learning models. Key strategies include:
- Feature Selection: Identifying and selecting the most relevant and informative features from the dataset, eliminating noise and redundancy to enhance model performance.
- Feature Transformation: Transforming raw features through techniques such as scaling, normalization, and dimensionality reduction to improve the interpretability and predictive power of the model.
- Domain-specific Feature Engineering: Leveraging domain expertise to engineer domain-specific features that capture intricate relationships and nuances within the data, enhancing model performance and interpretability.
By mastering the art of feature engineering, data scientists can enhance their ability to extract meaningful insights from complex datasets, driving more accurate and robust predictions in various domains.
Interpretability and Explainability
Interpretability and explainability emerge as paramount considerations in enhancing perception, ensuring that machine learning models are transparent, understandable, and trustable. Key approaches include:
- Model-agnostic Techniques: Employing model-agnostic techniques such as SHAP (SHapley Additive exPlanations) values and LIME (Local Interpretable Model-agnostic Explanations) to provide interpretable explanations for model predictions.
- Simplifying Complex Models: Simplifying complex machine learning models such as deep neural networks into more interpretable counterparts, such as decision trees or rule-based models, to enhance transparency and understanding.
- Human-in-the-Loop Approaches: Integrating human-in-the-loop approaches that enable users to interactively explore and interrogate model predictions, fostering trust and confidence in the model’s outputs.
By prioritizing interpretability and explainability, organizations can enhance the transparency and trustworthiness of their machine learning models, empowering stakeholders to make informed decisions based on data-driven insights.
In essence, the techniques to enhance perception in data mining represent a confluence of innovation, creativity, and expertise, aimed at augmenting our ability to extract meaningful insights from complex datasets. By embracing data visualization, feature engineering, and interpretability and explainability, organizations can unlock new vistas of understanding and drive transformative change in an increasingly data-driven world.
Challenges and Limitations

Navigating the landscape of data mining entails confronting a myriad of challenges and limitations that can hinder the perception and interpretation of data, from ambiguity and uncertainty to ethical considerations. Here, we delve into the key obstacles that data miners encounter in their quest for insights and understanding, shedding light on the complexities inherent in the analytical process.
Ambiguity and Uncertainty
Ambiguity and uncertainty loom large in the realm of data mining, posing formidable challenges to our ability to derive clear, definitive insights from complex datasets. Key considerations include:
- Ambiguous Data: Dealing with data that lacks clarity or precision, leading to multiple interpretations and potential misinterpretations of the underlying information.
- Uncertain Outcomes: Grappling with uncertainty in predictive modeling and analysis, where future outcomes are probabilistic and subject to inherent variability and unpredictability.
- Incomplete Information: Confronting situations where data is incomplete or missing, hindering our ability to draw meaningful conclusions and make informed decisions based on the available information.
Addressing ambiguity and uncertainty requires a nuanced approach that encompasses robust methodologies, probabilistic reasoning, and a recognition of the inherent limitations of the data at hand.
Overfitting and Misinterpretation
Overfitting and misinterpretation pose significant challenges to the validity and reliability of data mining outcomes, undermining our ability to derive accurate insights from the data. Key considerations include:
- Overfitting: Occurring when a model learns to capture noise and random fluctuations in the data rather than true underlying patterns, leading to inflated performance metrics and poor generalization to new data.
- Misinterpretation: Arising from a lack of understanding or misapplication of analytical techniques, leading to erroneous conclusions and flawed decision-making based on flawed assumptions or faulty interpretations of the data.
- Biased Interpretations: Succumbing to cognitive biases and preconceived notions that skew our perceptions and interpretations of the data, leading to unwarranted conclusions or misjudgments.
Mitigating the risks of overfitting and misinterpretation requires rigorous validation procedures, transparent reporting of results, and a commitment to critical thinking and skepticism in the analytical process.
Ethical Considerations
Ethical considerations loom large in the practice of data mining, necessitating careful consideration of the potential societal impacts and implications of our analytical endeavors. Key considerations include:
- Privacy and Consent: Respecting individuals’ privacy rights and obtaining informed consent for the collection and use of their data, ensuring that ethical principles such as autonomy and respect for persons are upheld.
- Bias and Fairness: Addressing biases in the data and algorithms that may perpetuate discrimination or unfair treatment of certain groups, striving to ensure that data mining practices promote equity, diversity, and inclusion.
- Transparency and Accountability: Promoting transparency and accountability in data mining practices, including clear documentation of methodologies, disclosure of potential biases or limitations, and mechanisms for recourse and redress in the event of harm or injustice.
By prioritizing ethical considerations in data mining, organizations can foster trust, integrity, and social responsibility in their analytical endeavors, ensuring that the benefits of data-driven insights are realized in a manner that upholds ethical standards and respects the rights and dignity of individuals.
Future Directions
As we peer into the horizon of data mining, a plethora of exciting possibilities and opportunities emerge, paving the way for transformative advancements in perception-driven analytics. Here, we explore the future directions that promise to shape the landscape of data mining in the years to come, from advancements in perception-driven data mining to the integration with artificial intelligence and the ethical and regulatory implications that accompany these developments.
Advancements in Perception-driven Data Mining
The future of data mining holds immense promise for advancements in perception-driven analytics, leveraging cutting-edge technologies and methodologies to enhance our ability to perceive, interpret, and derive insights from complex datasets. Key areas of focus include:
- Advanced Data Visualization Techniques: Harnessing the power of immersive and interactive data visualization technologies, such as augmented reality and virtual reality, to create compelling visual representations that facilitate deeper understanding and exploration of data.
- Cognitive Computing and Natural Language Processing: Integrating cognitive computing capabilities and natural language processing algorithms to enable more intuitive and conversational interactions with data, empowering users to extract insights through natural language queries and dialogue-based interfaces.
- Context-aware Analytics: Developing context-aware analytics frameworks that adapt to the situational context and user preferences, tailoring the presentation and interpretation of data to align with specific goals, objectives, and decision-making contexts.
By embracing these advancements in perception-driven data mining, organizations can unlock new vistas of understanding and innovation, driving enhanced decision-making, and strategic insights in an increasingly data-driven world.
Integration with Artificial Intelligence
The integration of perception-driven data mining with artificial intelligence represents a paradigm shift in the analytical landscape, offering unprecedented opportunities for automation, optimization, and innovation. Key developments include:
- Machine Learning-driven Insights: Leveraging machine learning algorithms to automate the process of data analysis, pattern recognition, and insight generation, enabling organizations to extract actionable insights from vast amounts of data with speed and efficiency.
- Deep Learning and Neural Networks: Harnessing the power of deep learning and neural networks to uncover intricate patterns and relationships within data, facilitating more accurate predictions and personalized recommendations across a wide range of domains and applications.
- Explainable AI: Advancing efforts to develop explainable AI models that provide transparent and interpretable explanations for their predictions and decisions, enhancing trust, accountability, and understanding in the analytical process.
By integrating perception-driven data mining with artificial intelligence, organizations can unlock new frontiers of innovation and efficiency, driving tangible business outcomes and competitive advantage in an increasingly AI-driven world.
Ethical and Regulatory Implications
As data mining continues to evolve and proliferate, it is essential to address the ethical and regulatory implications that accompany these advancements, ensuring that data-driven technologies are deployed responsibly and ethically. Key considerations include:
- Privacy and Data Protection: Strengthening privacy regulations and data protection measures to safeguard individuals’ rights and freedoms in the era of big data and pervasive analytics, balancing the need for innovation with the imperative to respect privacy and confidentiality.
- Bias and Fairness: Mitigating bias and promoting fairness in data mining algorithms and models to prevent discriminatory outcomes and ensure equitable treatment for all individuals, irrespective of demographic characteristics or socio-economic status.
- Transparency and Accountability: Promoting transparency and accountability in data mining practices, including clear documentation of methodologies, disclosure of potential biases or limitations, and mechanisms for recourse and redress in the event of harm or injustice.
By addressing these ethical and regulatory considerations proactively, organizations can foster trust, integrity, and social responsibility in their data-driven endeavors, ensuring that the benefits of data mining are realized in a manner that upholds ethical standards and respects the rights and dignity of individuals.
Case Studies and Examples
Explore real-world applications that vividly illustrate the power of perception-driven data mining in action, showcasing how organizations leverage advanced analytical techniques to derive actionable insights and drive transformative outcomes across diverse domains and industries.
Healthcare
In the realm of healthcare, perception-driven data mining plays a pivotal role in revolutionizing patient care, treatment protocols, and disease management strategies. Case in point, the application of machine learning algorithms to medical imaging data enables radiologists to detect and diagnose diseases such as cancer with unprecedented accuracy and efficiency. For example, researchers at Stanford University developed a deep learning algorithm known as CheXNet, which analyzes chest X-rays to identify pathologies such as pneumonia, tuberculosis, and lung nodules. By leveraging the power of perception-driven data mining, healthcare providers can expedite diagnosis, optimize treatment plans, and ultimately save lives.
Finance and Banking
In the finance and banking sector, perception-driven data mining serves as a catalyst for innovation, risk management, and customer engagement. Consider the case of fraud detection, where financial institutions employ sophisticated machine learning models to analyze transaction data and detect anomalous behavior indicative of fraudulent activity. For instance, PayPal utilizes a combination of machine learning algorithms and behavioral analytics to identify and prevent fraudulent transactions in real-time, safeguarding millions of users and billions of dollars in transactions annually. By harnessing the power of perception-driven data mining, financial institutions can mitigate risks, enhance security, and foster trust and confidence among customers in an increasingly digital and interconnected world.
Retail and E-commerce
In the retail and e-commerce landscape, perception-driven data mining drives personalized customer experiences, targeted marketing campaigns, and demand forecasting strategies. Take the example of recommendation systems, which leverage machine learning algorithms to analyze past purchase history, browsing behavior, and demographic information to suggest relevant products and services to customers. Amazon, for instance, employs a sophisticated recommendation engine that uses collaborative filtering and deep learning techniques to deliver personalized product recommendations to millions of users worldwide, driving sales and customer satisfaction. By embracing perception-driven data mining, retailers can optimize product offerings, enhance customer engagement, and gain a competitive edge in the dynamic and rapidly evolving e-commerce landscape.
Manufacturing and Supply Chain
In the realm of manufacturing and supply chain management, perception-driven data mining enables organizations to optimize production processes, improve supply chain visibility, and enhance operational efficiency. For example, predictive maintenance algorithms leverage sensor data and machine learning techniques to anticipate equipment failures before they occur, enabling proactive maintenance interventions and minimizing costly downtime. General Electric (GE) utilizes predictive maintenance algorithms in its aviation division to monitor aircraft engines in real-time and identify potential issues before they impact performance or safety. By harnessing perception-driven data mining, manufacturers can streamline operations, reduce costs, and ensure the reliability and resilience of their production infrastructure.